

Raspberry Pi InfluxDB 2.x (FLUX) - Daten problemlos mit Telegraf auf Grafana anzeigen
Du fragst dich, wie du dein System “Raspberry Pi influxdb 2.x ready” machen kannst? Da es die InfluxDB in einer neueren Version (2.x) gibt und hier einiges geändert wurde, gibt es vieles zu beachten, wenn man diese nutzen möchte.Vorab: hast du bereits die V1.8 im Einsatz und sammelst dort fleißig Daten, dann belasse es lieber so. Auch wenn du gerne auf fertige Grafana Dashboards zurückgreifst, bleibe bei der V1.8!Ansonsten zeige ich dir hier einige Stolpersteine und wie man die influxDB 2.x mit Telegraf und Grafana auf einem 64bit(!!!) Raspberry betreiben kann.
DarkWolfCave.de


Raspberry Pi Daten auf Grafana mit influxDB 2.x anzeigen - Was brauchen wir?
Wer meine Tutorials verfolgt, weiß, dass ich alles auf einem Raspberry Pi 4 betreibe. Daher beziehe ich mich auch nur auf diesen. Andere Linux-Systeme unterscheiden sich aber nicht wirklich und es sollte auch dort laufen.
Influxdb in der Version 2.x läuft NUR unter einem echten 64bit Betriebssystem! Es reicht NICHT nur den Kernel auf 64bit umzustellen!
Ansonsten benötigen wir noch:
- 64bit Raspberry Pi (oder eine 64bit Linux Umgebung)
- installierte Docker-Umgebung
- installierter Portainer-Container (nicht zwingend erforderlich, hierüber installiere ich aber den Container für Grafana und die influxDB V2.x)
- ein Grafana Docker Image
- InfluxDB Docker Image
- Telegraf
Hardware für InfluxDB, Grafana und Co.
Monitoring Hardware
Produktbilder ausgeblendet. Beim Laden wird deine IP-Adresse an Amazon übermittelt.
| Bild | Produkt | Preis | |
|---|---|---|---|
| Produktdaten werden geladen... | |||
Anmerkung zu Raspberry Pi influxdb 2.x
Ich muss es einfach nochmal loswerden. Solltest du bereits influxdb 1.8 nutzen und überlegen auf 2.0 zu updaten: Lass es lieber! Es gibt zwar die Möglichkeit seine Daten mitzunehmen, aber spätestens bei den Grafana-Dashboards wirst du dich ärgern. Denn influxdb 2.x nutzt “flux” und nicht mehr “influxQL” als Query Language. Somit sind alle deine (und fast alle die du bei Grafana finden kannst) Dashboards nicht mehr funktionsfähig.
Das bedeutet: du müsstest dir selbst ein neues Dashboard erstellen. Dazu benötigst du aber Wissen über die entsprechenden Queries usw (ok… hier unterstützt influxdb noch recht gut). Falls du sogar bereits deine Unifi-Geräte mit unpoller überwachst: Dies läuft nicht unter influxdb 2.x! Achja…erwähnte ich bereits, dass du zwingend ein 64bit Betriebssystem für influxdb 2.x benötigst?!
So genug davon. Solltest du dennoch deinen Raspberry Pi influxDB 2.x ready machen und die 2er Version ausprobieren wollen, zeige ich dir jetzt endlich wie du dabei vorgehen solltest.
Raspberry Pi Influxdb 2.x mit Portainer installieren
Bevor wir loslegen nochmal kurz zur Erinnerung: Ich gehe hier davon aus, dass du ein 64bit Betriebssystem (NICHT nur den Kernel) sowie Docker, Portainer und Grafana bereits installiert hast. Falls nicht: weiter oben sind die entsprechenden Links zu meinen Artikeln hinterlegt.
Verbinde dich zuerst mit deinem Raspberry über SSH (Putty, MobaXterm usw.) um einen persistenten Speicherort für die influxdb-Dateien anzulegen. Diesen binden / verbinden wir später bei der Installation des Containers. Ich lege solche Ordner meistens unter /opt an:
sudo mkdir /opt/influxdb_2x
sudo chmod 775 /opt/influxdb_2xDa wir die influxdb über Portainer installieren wollen, logge dich entsprechend über die Web-Gui ein: https://IP-deines-Raspberrys:9443 Über das Menü auf der Linken Seite wählst du “Containers” aus:

Wir wollen einen neuen Container erstellen, daher nutzen wir ”+ Add container”:

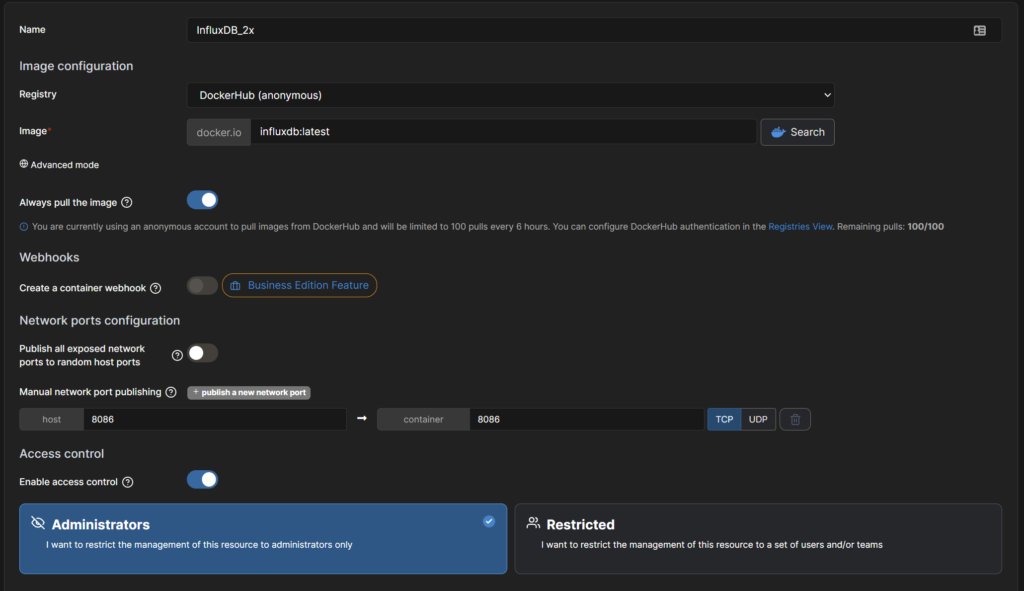
Hier können wir jetzt diverse Einstellungen vornehmen und natürlich einen Namen vergeben (z.B.: influxDB_2x)
- Name: influxDB_2x
- Image: influxdb:2
- “+publish a new network port” klicken und host:8086 sowie container: 8086 eintragen
Ab April 2026 zeigt der Docker-Tag influxdb:latest auf InfluxDB 3 - ein komplett anderes Produkt (SQL statt Flux, andere API). Nutze daher immer influxdb:2, damit du nur Minor-Updates innerhalb der 2.x-Linie bekommst.
Im unteren Bereich müssen wir auch noch ein paar Einstellungen ändern bzw einrichten:
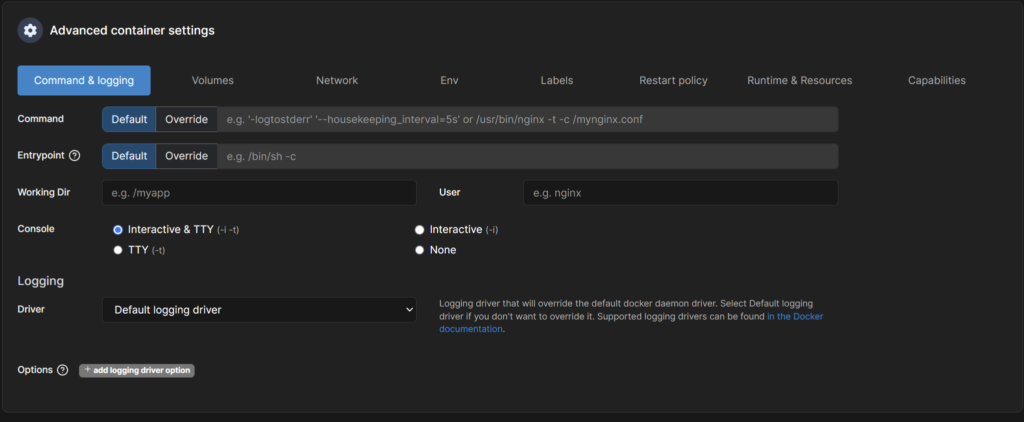
- Tab “Command & Logging” - Console: Interactive&TTY
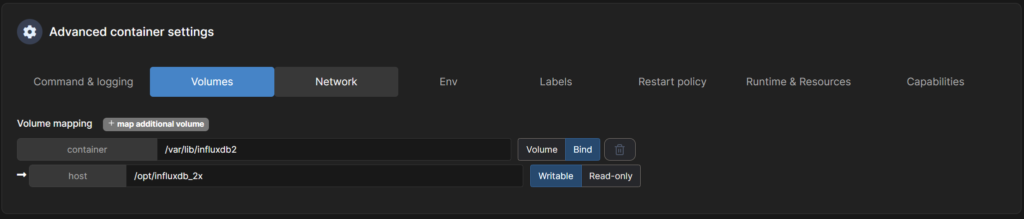
- Tab “Volumes” - ”+ map additional volume” klicken und bei container: /var/lib/influxdb2 eingeben, von Volume auf Bind wechseln und bei host den Bereich auf deinem Raspberry eintragen wo die persistenten Daten hinterlegt werden sollen: /opt/influxdb_2x
- Tab “Restart policy” - am besten “always” auswählen
- Der Rest kann bleiben wie es ist, bzw. muss dort nichts weiter eingestellt werden
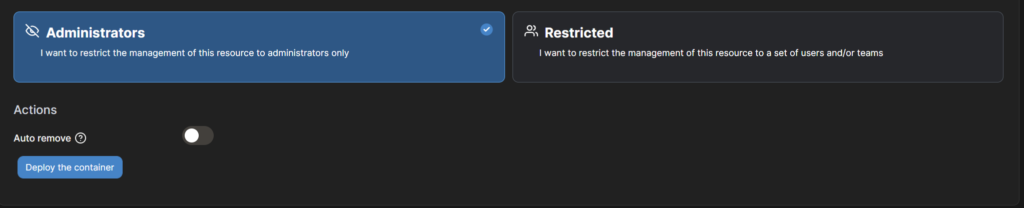
- auf “Deploy the container” klicken und der Container wird bereitgestellt

Nach dem “Deploy” wird das Image heruntergeladen und der Container erstellt. Dies kann etwas Zeit in Anspruch nehmen. Sollte alles funktioniert haben, kannst du dich auf die Web-GUI der influxDB einloggen: http:IP-DEINES-RASPBERRY:8086
Raspberry Pi Influxdb 2.x konfigurieren
Es gibt noch weitere Dinge die wir einrichten müssen bis unser System Raspberry Pi InfluxDB 2.x ready ist. Dieses können wir per CLI (Terminal) oder auch recht komfortabel über die Web-GUI vornehmen. Aktuell zeige ich dir die notwendigen Schritten in der Web-GUI.
Also drücke mal auf den Button “Get Started” nachdem du überhttp:IP-DEINES-RASPBERRY:8086 die GUI aufgerufen hast. Hier füllst du entsprechend die Felder aus:
- Username: Name des Users (Beispiel: admin)
- Password: Passwort… (Beispiel: admin123)
- Initial Organization Name: Vergleichbar mit “Name der Datenbank” (Beispiel: dwc_influxdb)
- Initial Bucket Name: Vergleichbar mit “Tabellenname” einer db (Beispiel: dwc_raspberry)
- Continue drücken
- Danach ist es eigentlich egal, aber klick mal auf “Quick Start”

Über diese Web-Oberfläche kannst du jetzt deine Datenbank weiter einrichten, bzw. Dashboards erstellen, Queries ausführen, Alarme setzen usw. Da ich die influxDB eher als reine Datenbank nutze, interessieren mich hier die Punkte Dashboards und Alerts nicht wirklich. Diese würde ich dann ja über Grafana einrichten.
Es gibt aber zwei wichtige Dinge hier:
- Load Data → API Tokens
- Data Explorer
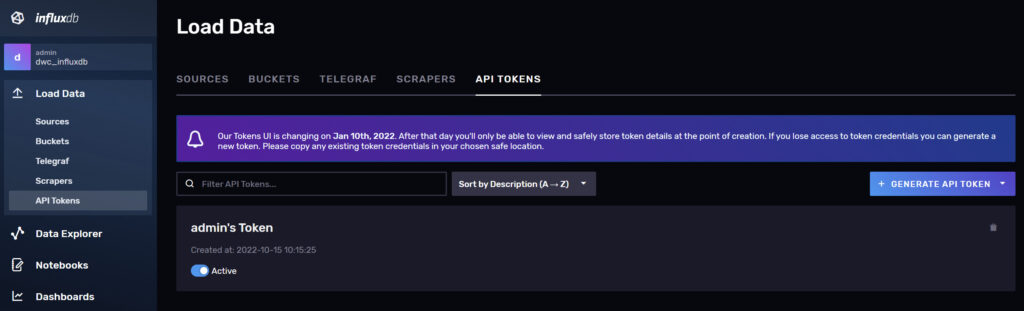
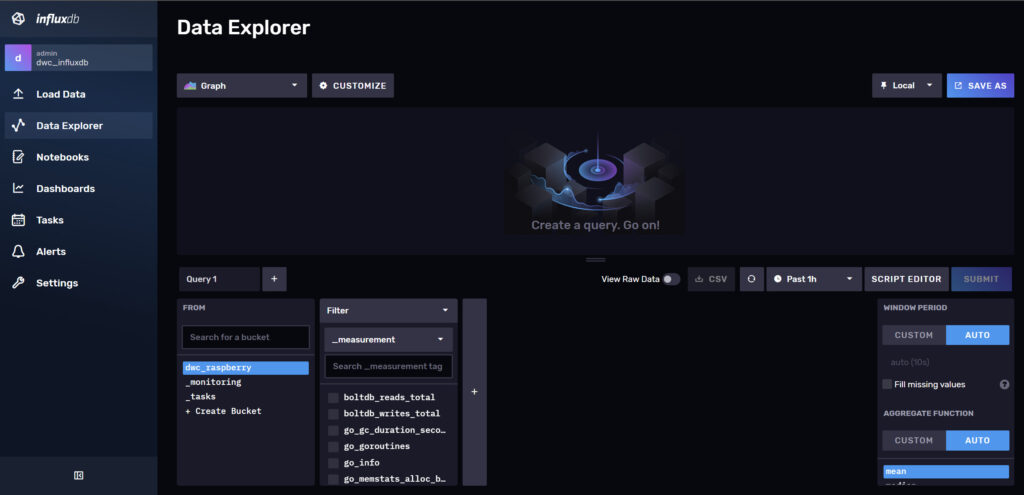
Raspberry Pi Influxdb 2.x - API Token
Eine der wichtigen Änderungen gegenüber der influxdb 1.8 ist zum Beispiel die zwingende gesicherte Verbindung zu der Datenbank. Dafür benötigen wir in jedem Script, welches eine Verbindung zum schreiben oder zum lesen aufbaut, einen entsprechenden Token. Diesen findest du über den Menüpunkt “Load Data”→ “API Tokens”.
Hier siehst du dann aktuell nur einen Eintrag. Und zwar von unserem gerade eingerichteten Admin-User (auf den Namen klicken und du kannst den Token in die Zwischenablage kopieren) Selbstverständlich kannst du weitere User und weitere Token (nur schreib/lese Rechte, nur für bestimmte Buckets (Tabellen) ) einrichten. Ich nutze in dem Beispiel den Admin-Token. Dieser hat allerdings dann Vollzugriff auf sämtliche Einstellungen. Im eigenen Umfeld kein Problem, in einem geteilten Netzwerk so lieber nicht nutzen.
Raspberry Pi Influxdb 2.x - Data Explorer
Die andere komplette Änderung ist die “Sprache” um die Datenbank abzufragen. Seit 2.x nutzt influxdb “Flux” und nicht mehr “influxQL”. Somit sind, zum Beispiel in den “alten” Grafana-Dashboards, alle alten Abfragen nicht mehr ohne weiteres mit der 2.x Version nutzbar.
Über den Menüpunkt “Data Explorer” kannst du per Auswahl deine benötigten Abfragen erstellen und diese dann sogar als Code über den Button “Script Editor” ausgeben und für Grafana nutzen. Da wir aktuell eine frische und leere Datenbank erstellt haben, werden wir hier noch nicht viel sehen. Kommen da aber später nochmal drauf zurück.
Raspberry Pi InfluxDB 2.x API Token in Variable speichern
Wie gerade erklärt, benötigen wir für jede Datenbankverbindung einen Token. Diesen müssen wir natürlich auch in unsere Scripte bringen, damit wir die Berechtigungen erhalten etwas in die InfluxDB zu schreiben bzw. von dort zu lesen.
Wie bekomme ich den Token in eine Variable?
Erst einmal besorgen wir uns den Token. Dafür, wie bereits erwähnt, gehe auf die Weboberfläche der InfluxDB (IP-DEINES-RASPBERRYS:8086), logge dich ein und rufe das Menü “Load Data” → “API Tokens” auf. Danach klickst du auf den Namen (z.B. admin´s Token) und kopierst diesen.
Jetzt fragst du dich vielleicht, wie du diese Variable in die entsprechenden Scripte bekommst damit auch diese * Raspberry Pi InfluxDB 2.x ready* sind?
Tja…da es sehr viele unterschiedliche Scripte gibt, die auch noch alle anders von der Syntax her aufgebaut sind, kann ich dir das so pauschal nicht sagen.
Ein leichter Ansatz wäre es, auf der entsprechenden Linux-Umgebung mit EXPORT den Token in eine globale Variable zu stecken und diese dann in einem Script ansprechen (export INFLUX_TOKEN=DEIN_TOKEN_AUS_DER_INFLUXDB_DATENBANK).
Aber: Die meisten werden sicherlich telegraf benutzen, um Daten von einem Raspberry in die influxdb zu schreiben. Und wie das geht erkläre ich dir im nächsten Kapitel ;-)
Telegraf und die neue Variable mit dem Token
Auch hier gibt es wieder verschiedene Möglichkeiten (sogar über die InfluxDB Web-Gui) um Telegraf richtig einzurichten. Dieses mal nutze ich aber das Terminal und konfiguriere die telegraf.conf direkt, da ich hier dann auch schon ein paar PlugIns (für die Metriken) integriert habe.
Ich gehe davon aus, dass du die neueste telegraf Version installiert hast, und diese NICHT bereits für InfluxDB1.8 benutzt! Denn ansonsten würdest du mit den nächsten Schritten deine alte Konfiguration zerstören und somit keine Daten mehr an die InfluxDB 1.8 senden!
Na dann mal los. Falls noch nicht geschehen, starte eine SSH-Verbindung zu deinem Raspberry und editiere folgende Datei:
sudo nano /etc/telegraf/telegraf.confAm besten du löscht dort alles und fügst dann den etwas weiter unten aufgezeigten Inhalt ein. Allerdings musst du einige Werte an deine anpassen:
- urls: Hier gibst du die URL zu der Instanz an, auf dem der Container mit der InfluxDB läuft ( meist IP des Raspberry und Port :8086 )
- token: hier fügst du den gerade kopierten Token aus deiner InfluxDB ein
- organization: hier gibst du den Namen an, welchen du weiter oben bei Initial Organization Name: Vergleichbar mit “Name der Datenbank” (Beispiel: dwc_influxdb) eingerichtet hast
- bucket: auch hier muss der Eintrag hinein, so wie du ihn oben unter Initial Bucket Name: Vergleichbar mit “Tabellenname” einer db (Beispiel: dwc_raspberry) eingegeben hast
- den Rest kannst du so lassen, bzw. ist dieser eh auskommentiert und wird nicht genutzt
Hinweis bei einem 64bit System (welches überwacht werden soll)
CaJa hat in den Kommentaren netterweise den Hinweis gegeben, dass ein Verzeichnis bei einem 64bit System anders lauten muss. Dies betrifft dich nur dann, wenn dein überwachtes System auch auf 64bit läuft. Im Quelltext habe ich jetzt entsprechende Änderungen hinzugefügt. Du musst dann lediglich die Raute (#) verschieben. Je nachdem ob 32bit oder 64bit.
[[inputs.exec]]
#Für ein 32bit System (welches überwacht werden soll)
commands = ["/opt/vc/bin/vcgencmd measure_temp"]
#oder für ein 64bit System (welches überwacht werden soll), dann die Raute(#) entfernen und bei 32bit die Raute hinzufügen
# commands = ["/usr/bin/vcgencmd measure_temp"]Hier jetzt der komplette Inhalt der telegraf.conf:
# Configuration for sending metrics to InfluxDB 2.0
[[outputs.influxdb_v2]]
urls = ["http://IP-DEINES-RASPBERRYS:8086"]
token = "DEIN TOKEN AUS DER INFLUXDB"
organization = "DEINE DATENBANK"
bucket = "DEINE TABELLE"
## Timeout for HTTP messages.
timeout = "15s"
## HTTP/2 Connection Keep-Alive (verhindert tote Verbindungen im Pool)
read_idle_timeout = "30s"
ping_timeout = "15s"
## Komprimierung aktivieren - reduziert die Datenmenge
content_encoding = "gzip"
#In order to monitor both Network interfaces, eth0 and wlan0, uncomment, or add the next:
[[inputs.net]]
[[inputs.netstat]]
[[inputs.file]]
files = ["/sys/class/thermal/thermal_zone0/temp"]
name_override = "cpu_temperature"
data_format = "value"
data_type = "integer"
[[inputs.exec]]
#Für ein 32bit System (welches überwacht werden soll)
commands = ["/opt/vc/bin/vcgencmd measure_temp"]
#oder für ein 64bit System (welches überwacht werden soll), dann die Raute(#) entfernen und bei 32bit die Raute hinzufügen
# commands = ["/usr/bin/vcgencmd measure_temp"]
name_override = "gpu_temperature"
data_format = "grok"
grok_patterns = ["%{NUMBER:value:float}"]
# Read metrics about cpu usage
[[inputs.cpu]]
percpu = true
totalcpu = true
collect_cpu_time = false
report_active = false
# Read metrics about disk usage by mount point
[[inputs.disk]]
ignore_fs = ["tmpfs", "devtmpfs", "devfs", "iso9660", "overlay", "aufs", "squashfs"]
# Read metrics about disk IO by device
[[inputs.diskio]]
# Get kernel statistics from /proc/stat
[[inputs.kernel]]
# Read metrics about memory usage
[[inputs.mem]]
# Get the number of processes and group them by status
[[inputs.processes]]
# Read metrics about swap memory usage
[[inputs.swap]]
# Read metrics about system load & uptime
[[inputs.system]]Falls du InfluxDB 2.8.0 oder neuer nutzt, sind die Einstellungen read_idle_timeout und ping_timeout wichtig! Ohne diese kann es passieren, dass Telegraf auf tote HTTP/2-Verbindungen schreibt und alle Writes mit Timeout-Fehlern fehlschlagen. Die beiden Zeilen aktivieren HTTP/2 PING-Frames, die solche toten Verbindungen automatisch erkennen und ersetzen.
Speichern nicht vergessen! Damit Telegraf einige Daten auch erhält, muss der User noch in die Video Gruppe integriert werden:
sudo usermod -G video telegrafNun den Telegraf-Service neu starten:
sudo systemctl restart telegraf.serviceAb jetzt sollte Telegraf Daten an InfluxDB senden. Prüfen kannst du es unter anderem auf der Weboberfläche von deiner InfluxDB.

Du willst dein Monitoring nicht selbst einrichten? Ich übernehme das für dich — schau dir meine Services an
Grafana für InfluxDB 2.x konfigurieren und Dashboard hinzufügen
Ist unser System etwa noch immer nicht Raspberry Pi InfluxDB 2.x ready?! Nein…noch nicht ganz. Bisher haben wir jetzt das sammeln der Daten erledigt. Aber sehen können wir sie - zumindest in Grafana - noch nicht. Dazu benötigen wir noch ein paar weitere Schritte. Auch hier gehe ich ganz frech davon aus, dass du Grafana bereits installiert hast. Falls nicht… schaue dir diesen Artikel von mir nochmal an.
Wo kann man etwas konfigurieren? Genau! Unter anderem über eine Weboberfläche. Also fixhttp://IP-DEINES-RASPBERRY:3000 aufrufen, einloggen und schon geht es mit einer neuen Verbindung von Grafana zur InfluxDB 2.x Datenbank los.
Dazu musst du in dem Menü auf der linken Seite lediglich auf das Zahnrad gehen, danach Data sources wählen und auf den blauen Button Add data source klicken.

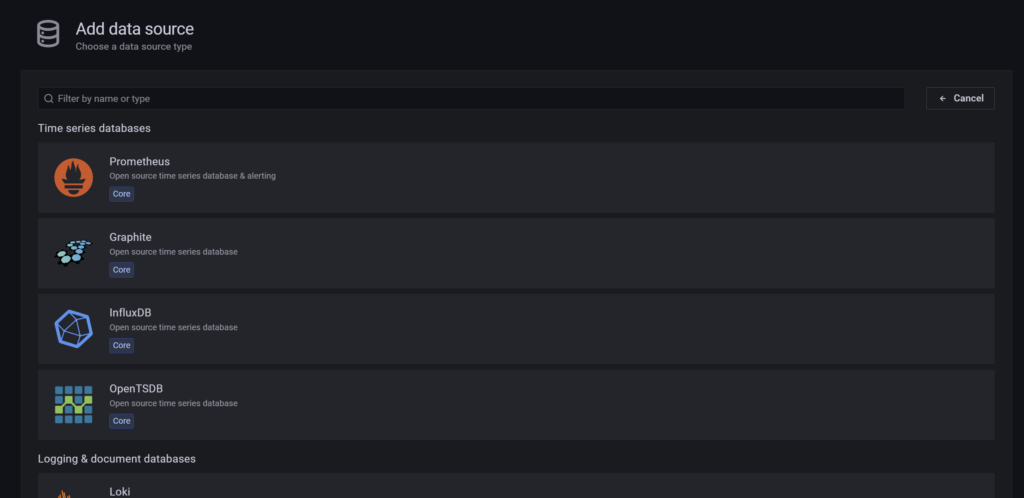
Hier benötigen wir InfluxDB:
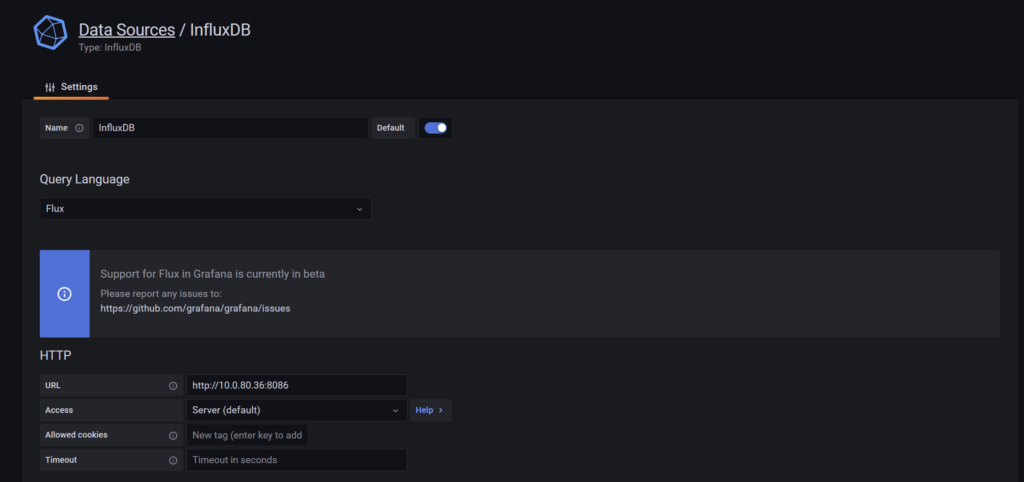
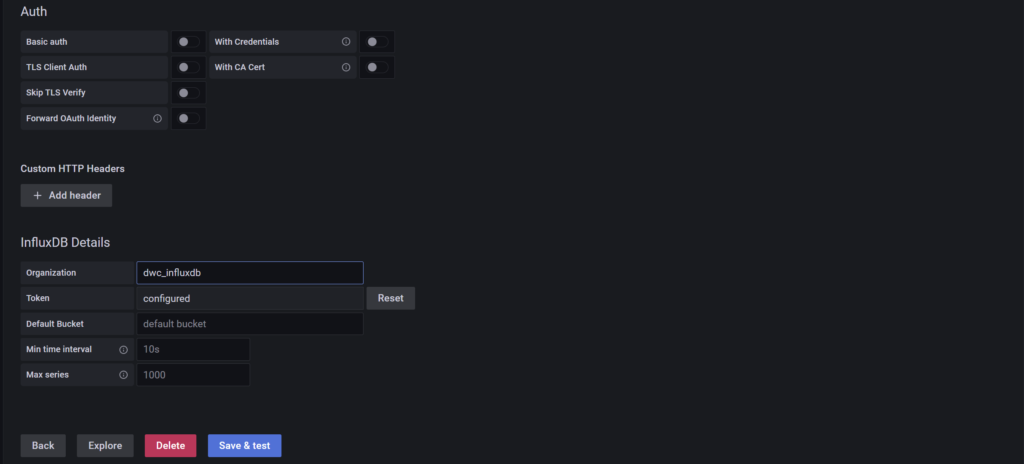
Bei den Settings brauchen wir jetzt folgendes um unser System weiter in Richtung *Raspberry Pi InfluxDB 2.x ready *zu bringen:
- Name: Name unter der diese Verbindung gespeichert werden soll (z.B. InfluxDB)
- Query Language: WICHTIG: auf Flux ändern. Denn dies wird für die InfluxDB 2.x benötigt
- URL: Hier kommt die IP und der Port zu deiner InfluxDB hinein (z.B.: IP-DEINES-RASPBERRY:8086)
- Basic Auth: bitte deaktivieren.
- Organization: Wie du es weiter oben unter “Initial Organization Name: Vergleichbar mit “Name der Datenbank” (Beispiel: dwc_influxdb)” eingerichtet hast
- Token: der Token, den wir auch schon für die Telegraf-Konfiguration benötigt haben
- Save & Test anklicken und hoffentlich keinen Fehler sehen
Und nu brauchen wir noch ein neues Dashboard. Ich habe es zwar auch bei Grafana hochgeladen, doch irgendwie wird es dort nicht angezeigt. Also verlinke ich die json-Datei hier und erkläre dir wie du diese bei dir einfügen kannst. Einfach rechtsklick auf den Link und “Link speichern unter” auswählen und bei dir speichern:
/wp-content/uploads/Telegraf-_-Raspberry-Metrics-InfluxDB-2.0-Flux-1665859102526.json
Nach ein paar Tagen ist das Dashboard jetzt doch auf der Grafana-Seite zu sehen. Du kannst also mein json-File von hier nutzen, es von der Grafana Seite laden oder über die ID 17191 importieren. Die Anleitung bezieht sich jetzt weiterhin nur auf das Import eines JSON-Files. Ansonsten würdest du bei der Import Seite nur die ID angeben und LOAD klicken.
Danach gehst du über die linke Menüleiste auf Dashboards und Import und wählst Upload JSON File:
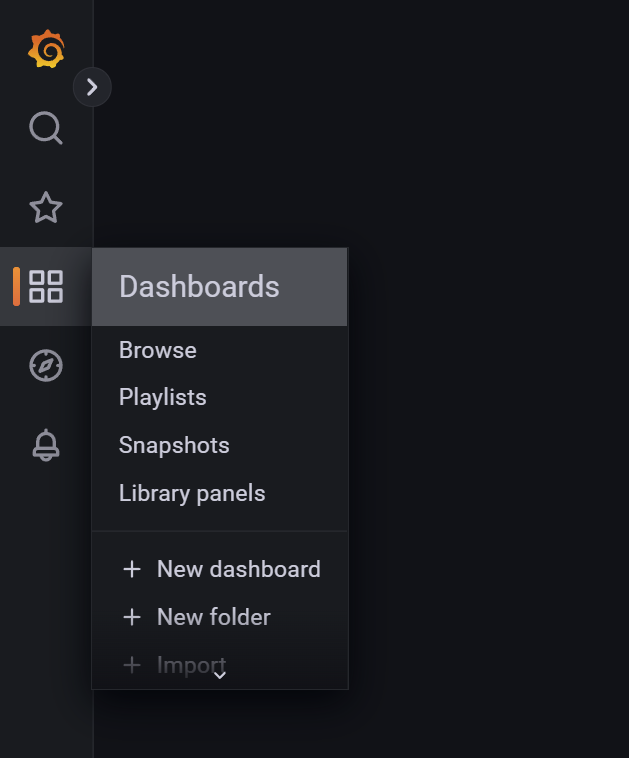
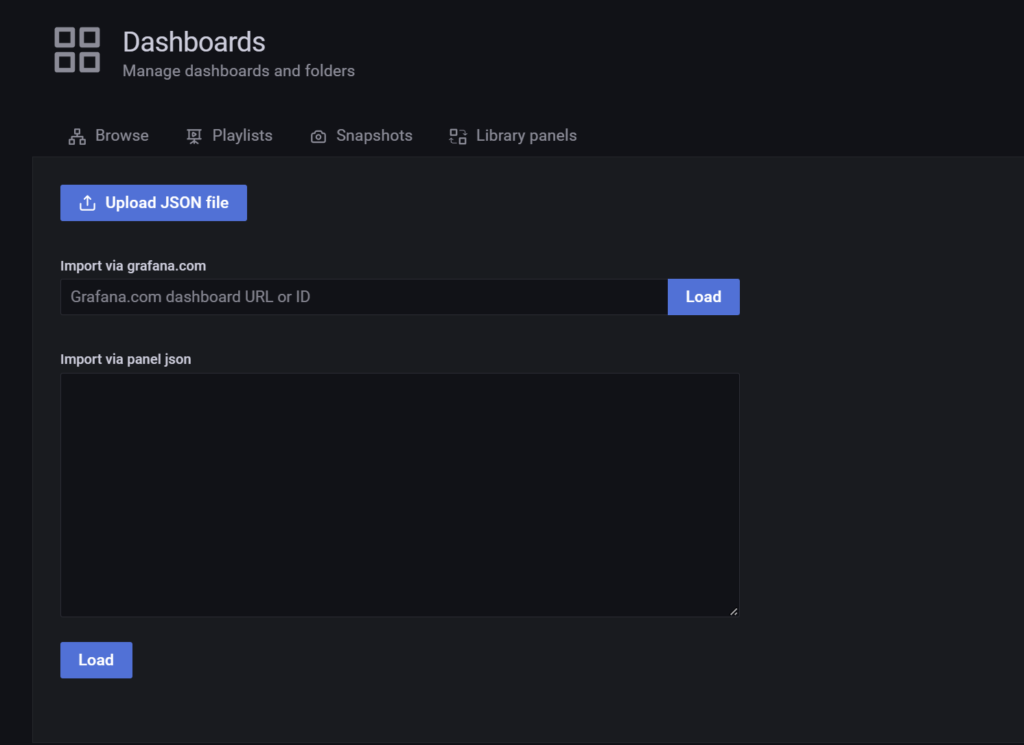
Jetzt noch das gerade heruntergeladenejson-File auswählen, Namen vergeben bzw. übernehmen. Bei influxDB die Verbindung einstellen (InfluxDB) und mit Import das Dashboard aktivieren.
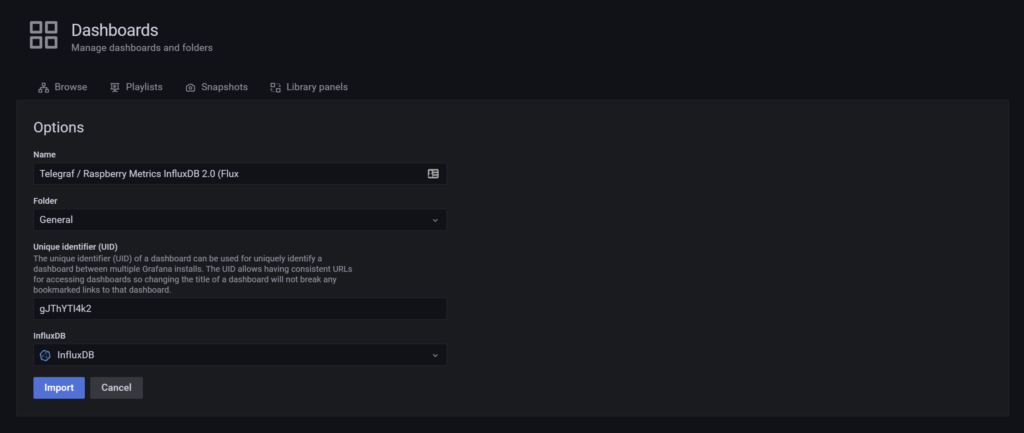
Als letzten Schritt bei bucket noch die richtige Tabelle auswählen ( wie du es in dem Schritt *“Initial Bucket Name: Vergleichbar mit “Tabellenname” einer db (Beispiel: dwc_raspberry” *eingerichtet hast). Und taaaadddaaaa!!! Siehst du hoffentlich so etwas:
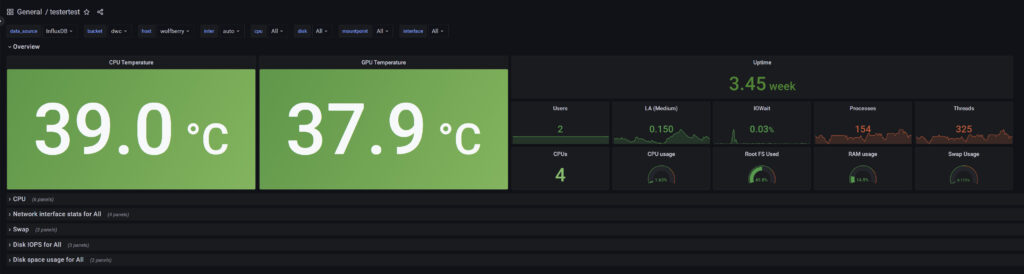
Herzlichen Glückwunsch! Dein System ist somit Raspberry Pi InfluxDB 2.x ready und einsatzbereit!

Du wirst hier einen groben Überblick finden.
Allerdings biete ich dir auch noch etwas mehr Support an:
- Du benötigst persönlichen Support
- Du möchtest von Beginn an Unterstützung bei deinem Projekt
- Du möchtest ein hier vorgestelltes Plugin durch mich installieren und einrichten lassen
- Du würdest gerne ein von mir erstelltes Script etwas mehr an deine Bedürfnisse anpassen
Für diese Punkte und noch einiges mehr habe ich einen limitierten VIP-Tarif eingerichtet.
Falls der Tarif gerade nicht verfügbar ist, kontaktiere mich auf Discord!


Kommentare